DL1
吴恩达深度学习(1/5)
[toc]
第一门课
第一周-前言(看不看无所谓)
1.1
1.2
1.3
1.4
1.5
第二周-神经网络基础
2.1
2.2 逻辑回归
sigmod(wTx(i)+b)
我们还可以使用 ReLU 函数,这样的速度可能会更快。
2.3 代价函数
损失函数又叫误差函数,用来衡量预测输出值和实际值有多接近,一般我们用预测值和实际值的平方差或者它们平方差的一半,但通常我们不使用。
为什么不使用平方差呢?
通常在逻辑回归中我们不这么做,因为 当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
我们这样设计单个样本的损失函数: L(y^,y)=−ylog(y^)−(1−y)log(1−y^)
预测值 $\hat{y}$
于是,全部训练样本的损失函数:
注意⚠️损失函数只适用于单个训练样本,而代价函数是参数的总代价。
2.4 梯度下降
以上,我们目前有以下公式:
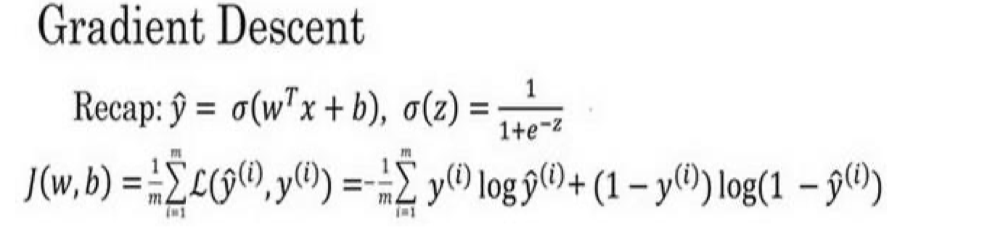
如何更新参数
2.5 关于导数的讲解(跳过)
2.6 导数的补充(跳过)
2.7 计算图
一个神经网络的计算,都是按照前向或反向传播过程组织的。
首先我们计算出 一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。后者我们用来计算出对应的梯度或导数。计算图解释了为什么我们用这种方式组织这些计算过程。
很简单。比如$J(a,b,c)=3(a+bc)$,实际上是我们经历了
step1:U=bc
step2:V=a+u
step3:J=3V

2.8 使用计算图求导
利用计算图,可以很方便的看出一个参数对整体代价函数的影响。
比如我们讨论a对J的影响大小。那么我们想a增加0.01,那么V就增加0.01,J就增加0.03(根据流程图来看)。
因此,最后a对J的影响就是'da=3',即$\frac{dJ}{da}=3$
其他可以自己试试b和c对J的影响。
答案是b对J的影响是3c。c对J的影响是2b。(b,c带入具体值)。
(其实就是链式法则,学过高数的应该觉得很简单,考过研的应该觉得就这?是的,就是和你想的一样,就这。)
补充一个编程小知识:如何在编程命名(如上式子dJ/da)。
dFindOutputvar_dvar变量命名为dJ_dvar
dvar就用dvar
2.9 逻辑回归中的梯度下降
但是在本节视频中,我将使用计算图对梯度下降算法进行计算,使用计算图来计算逻辑回归的梯度下降算法有点大材小用了。
但是,我认为以这个例子作为开始来讲解,可以使你更好的理解背后的思想。从而在讨论神经网络时,你可以更深刻而全面地理解神经网络。

我们求出代价函数(单个样本叫损失函数)最小,我们要做的是修改参数w和b(调参)。
我们主要讨论这个反向传播的部分。
(1)首先,我们先反向计算出代价函数$L(a,y)$关于a的导数,在编写代码时,你只需要用da来表示$\frac{dL(a,y)}{da}$
对公式求偏导发现。 
注意

(2)然后计算z的 
(3)最后计算w和b的
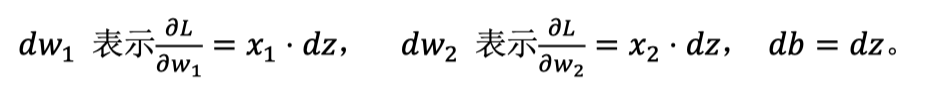
我们使用上面👆式子来计算单个样本实例的梯度下降算法中参数更新一次的步骤。
step1:根据$dz = (a-y)$计算$dz$
step2:使用公式计算dw,db dw1=x1∗dzdw2=x2∗dzdb=dz
step3:更新参数 dw1=w1−α∗dw1dw2=w2−α∗dw2db=dz
整个过程浓缩成下图 
如果还是没看懂,也不用慌,原因是,这个例子非常简单,但是由于我们要编程给计算机使用,因此这个分解的过程非常重要。
我们可以跳出来,以大局观看一看。
实际上是对$\sigma(w_1x_1+w_2x_2+b)$这个式子求导w1,w2,b。
举个w1来看,我们根据链式法则先求$L()$的导数,是-y/a+(1-y)/(1-a)。然后求出$\sigma()$的导数,是a(1-a)。最后是z()的导数,是x1。
链式法则是将它们相乘,是我们最终要得到的w1对损失函数的影响,就是导数嘛!导数就是斜率,代表的是朝着目标的走向嘛!当导数(斜率)平稳了,不就代表我们已经训练完成了,到达了最优点(凸函数)。
$\sigma$是$\frac{1}{1-e^{-z}}$
a=$\sigma$
为了不同式子避免混淆,我们采用了新符号
害,链式法则就是我们平时的复合导数求导嘛!
2.10 m个样本的梯度下降
其实就是对多个单样本求平均,但是你不能用for循环吧,这样效率太低,因此引出向量化。
“弹幕里说,不是指写得快,是说运算快,哈哈哈哈,笑死我了”
2.11 向量化
没啥好说的直接上代码。
运行后会发现,向量化版本花费1.5ms,而非向量化版本是500多ms。
因此向量化的一分钟,是非向量化的5个小时。可怕如斯。
2.12 向量化的更多例子
矩阵计算也可以使用向量化,从而消去两层循环,也是使用np.dot()函数。
事实上,numpy中有许多向量函数,如
np.log()
np.abs()
np.maximun()
等都可以避免使用循环。

2.13 向量化逻辑回归
接下来,让我们带着向量化的思想,重新优化一遍逻辑回归。
首先,对W进行扩展成(nx,1)维向量;
然后,对X扩展成(nx,n)维向量,其中行代表样本数量,列代表每个样本的输入数量。
整个式子,变成了$Z = W^TX + b$。
这里在 Python 中有一个巧妙的地方,这里 𝑏 是一个实数,或者你可以说是一个 1 × 1 矩阵,只是一个普通的实数。但是当你将这个向量加上这个实数时,Python 自动把这个实数 𝑏 扩展成一个 1 × 𝑚 的行向量。 所以这种情况下的操作似乎有点不可思议,它在 Python 中被称作广播(brosdcasting)。
代码就变成了
2.14 向量化逻辑回归的梯度输出
接下来,我们优化激活函数a值,然后优化反向传播计算梯度。
先来观察👀原来的函数。 
先来看db。因为db=dZ,Z我们已经向量化了,因此直接函数np.sum()优化。即
然后看dw, 即
至此,所以步骤中的式子全部用向量的形式表示。
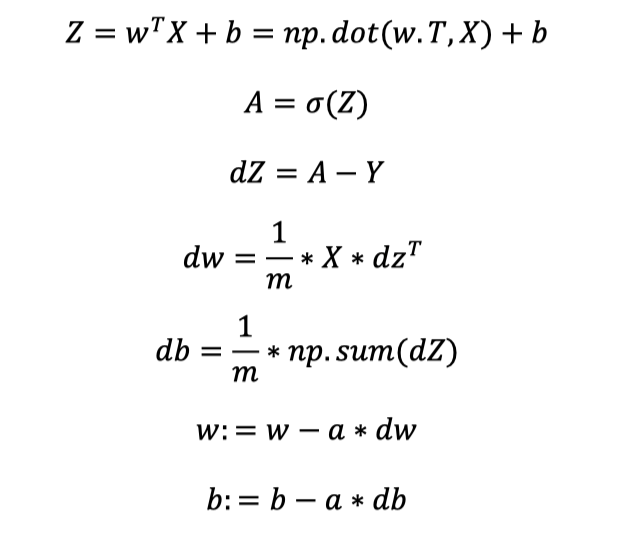
2.15 Pthon中的广播
这是一个新例子,来看看



广播机制的解释:
如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为 1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为 1 的维度上进行。

2.16 关于python numpy的说明
广播机制有好也有坏,好处我们已经知晓,但是坏处在哪呢?
例如,如果你将一个列向量 添加到一个行向量中,你会以为它报出维度不匹配或类型错误之类的错误,但是实际上你会得到一个行向量和列向量的求和。
因此,吴老师给我们传授一些编程技巧,比如
(1) 
Last updated